
近期,我们在生活中经常会听到关于机器学习与人工智能(AI)方面的信息。机器正学着模仿人类大脑,自动处理各类工作。能够自动驾驶的车辆则在学习了解驾驶路况,还有能够与人类对话的私人助手,以及像人类一样预测股票市场走势的机器等。从某些方面来说,机器学习简直像“魔法”一样神奇。
但在机器学习的背后,应用了许多基础性、深入研究过的技术。人类需要学习如何利用这些技术来解决某类问题。首先需要了解一下这些技术,再来说明发现存在不当访问非结构化数据问题时的解决方案。
机器学习――定义:
机器学习属于人工智能,计算机能够利用训练或观察学习到的算法来探测相关模式并确定其基准行为。机器学习能够处理与分析海量数据,这对于人类来说可不是轻而易举的事情。
机器学习任务主要分为两大类:
1、监督学习:向机器内输入各种资料,以及预期输出内容,如此,以后只要录入相关内容,就能得出预期输出。
2、无监督学习:此类机器用于在没有明确输入具体查询模式的前提下,检测数据集中的各类数据模式。
更重要的是,在无监督机器学习过程中,有多种技术可识别各类数据模式,最终生成有价值的分析结构。了解问题域是正确的选择应用技术的关键。数据专家们的主要任务之一就是要确定该使用哪种技术。如数据专家不了解问题域,则无法选择正确的方法解决问题。
聚类:
聚类是向同类组分配对象的过程(亦称为簇),旨在确保各组的对象都不同。聚类属于无监督任务,用于描述对象的隐藏结构。
各对象由一系列特点组成,称之为特征。划分对象到不同集群时,首先要确定各个对象间的距离。定义适当距离测量法是成功完成聚类的关键。
k-means:
目前有许多聚类算法可用,各有优缺点。常用的聚类算法就是 k-means,这种算法可以迭代法识别出最佳的k 聚类中心。聚类中心是与聚类相关的对象“代表”,k-means的主要优缺点如下:
1、必需明确指定聚类数量,但某些情况下无法知道各类聚类的数量;
2、k-means的迭代特性容易因局部最小值汇聚产生错误结果。
3、假设聚类是球状的。
虽然有这些缺点,但在许多情况下,k-means仍是最正确也是最常用的算法。关于球面数据使用k-means的聚类示例可见图1。
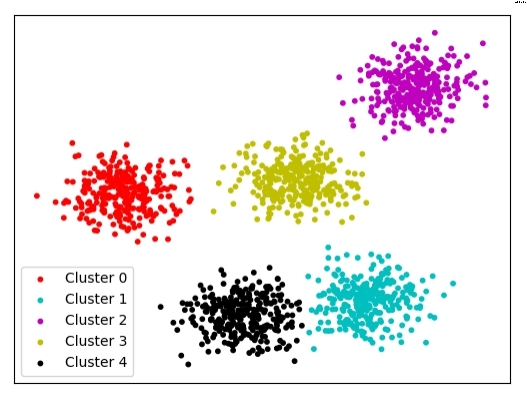
图1:球状数据上的k-means聚类
OPTICS 聚类算法:
另外一种聚类算法是OPTICS,它是基于密度的聚类算法。基于密度的聚类算法,与基于质心的聚类算法不同,这种算法通过识别点簇“密度”,了解任意形状与密度的聚类。OPTICS还可通过识别出分散的对象来确定数据的离群值(噪声)。
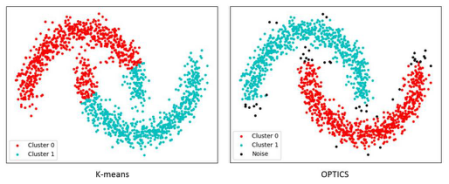
图2: k-means与OPTICS应用于数据时的对比
OPTICS与k-means算法会生成截然不同的数据点组;它会将离群值分类,并更为精确的按数据性质而非球状的方式来表现簇。可参见图2在数据上应用k-means及OPTICS后的对比示例。
降维:
在机器学习领域,通常针对高维数据采用降维法处理。此处理方法旨在减少需要考虑的各类特征数据,因为每项特征都代表了对象的一个部分。
为何降维如此重要?随着特征的增多,数据变的更加稀疏,因此需要从维度灾难方面进行分析。此外,还便于处理小型数据集。
利用以下两个方法执行降维:
1、从现有特征中选择(特征选择)
2、组合现有特征后,提取新特征(特征提取)。
特性提取的主要技术是主成份分析法(PCA)。主成份分析法可保证找到最佳线性变换,降低维数数量,减少信息损失。有时,丢失的信息被称为噪声,这种信息并不具有代表性,只是部分未知程序的副作用而已。主成份分析法的视觉表达如下(图3):
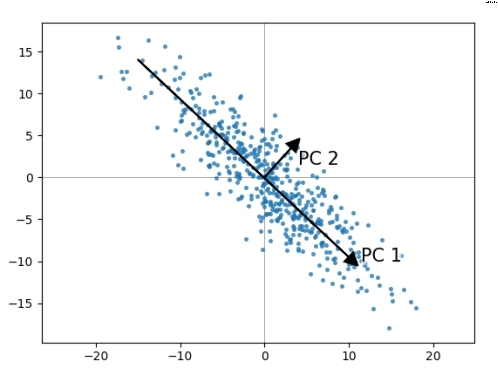
图3:主成份分析法
上述示例中,可能对PC1的结果表示满意,最终以一个特性取代了原来的两个特性。
有许多降维技术可选择:部分线性技术,如:主成份分析法,部分非线性技术以及后期日趋普遍使用的深度学习法等(词嵌入)。
将相关技术用于动态学习对等组:
Imperva Defense Center近期的黑客情报计划(HII)调查报告中提到了文件安全的最新创新方法。这种方法会利用无监督机器动态学习对等组。一旦学会了对等组,就可以用对等组来确定每个用户访问组织中的各种共享文档的虚拟权限是否正确。Imperva的违规防御解决方案CounterBreach中就使用了这种动态对等组功能。
图4介绍了如何根据动态对等组分析结果,利用机器学习探测可疑文件访问活动。
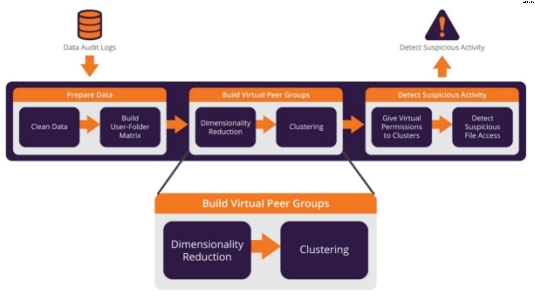
图4:利用动态对等组分析结果探测可疑活动的过程
首先Imperva将审计数据转化为用户访问目录的矩阵,其中横坐标为用户与纵坐标为文件夹。矩阵单元内的值为指定用户访问文件夹的活动量。然后,Imperva会进行降维的处理。使用PCA的首个原因就是矩阵的稀疏性,因为矩阵单元内99%以上都是空的。其次,许多文件夹的访问模式都是关联的,从而导致矩阵出现多重共线性。而实际上在我们的案例中,多组用户会在一个类似项目中工作,这些用户都有关联性,因此被放置在类似的文件夹组中。最后,使用PCA后,矩阵范围缩小了90%,因此更便于处理。收集与准备数据后,机器学习可构建虚拟对等组。Imperva利用前述机器学习技术(即:PCA以及基于密度的聚集法)构建动态对等组。
其次,Imperva选择OPTICS算法作为其聚集算法,即:根据密度来聚集用户。因为对等组数据未知,而k-means需要了解簇的数量――本案中为需要了解对等组数量,因此无法使用该算法。
OPTICS则不受此数据限制。OPTICS还便于采取特殊手段处理噪声用户,即:将噪声用户单独放入一个簇内。除上述原因外,经过大量的试验与辨错后,确认OPTICS是本数据集最佳算法。
小结:
选择正确的算法是数据分析三要素最重要的一个环节。数据分析三要素:首先就是数据本身,其次是数据准备工作,即:清理与选择能够代表数据特点的具体特征,第三就是利用正确的机器学习法,适当描述数据。
本案中,PCA与OPTICS都是经过证明,特别适用于学习对等工作组的工具。但“机器”并不能神奇的自我决策。只有人(也就是团队)才能了解问题所在,分析数据,并“魔法般的”选择正确的机器学习法构建人工智能的高楼大厦。

 您现在的位置:
您现在的位置: 火爆Java 、大数据公开课
火爆Java 、大数据公开课









 赣公网安备 36010902000737号
赣公网安备 36010902000737号